728x90
반응형

전체 데이터셋 : 1000개 데이터
batch size : 100
각 epoke 당 batch 수 : 10
네트워크 구성
ReLU -> ReLU -> softMax
세 개의 activation 함수를 통과 한다고 할때 10epoke는 무슨일이 일어나냐?
- 첫 번째 배치가 전체 네트워크(ReLU → ReLU → Softmax)를 통과합니다.
- 첫 번째 배치에 대한 손실을 계산하고 가중치를 업데이트합니다.
- 두 번째 배치가 전체 네트워크를 통과합니다.
- 두 번째 배치에 대한 손실을 계산하고 가중치를 업데이트합니다.
- ...
- 열 번째 배치가 전체 네트워크를 통과합니다.
- 열 번째 배치에 대한 손실을 계산하고 가중치를 업데이트합니다.
이렇게 10개의 배치가 모두 처리되면 1 에포크가 완료됩니다. 그 다음 2 에포크가 시작되어 같은 과정이 반복됩니다.
각 배치마다 네트워크의 모든 층(ReLU → ReLU → Softmax)을 통과하고, 모든 배치가 처리되어야 1 에포크가 완료된다고 보시면 됩니다.
그렇다면 Batch Norm은 무엇일까요?
배치 정규화(Batch Normalization, 줄여서 Batch Norm)는 딥러닝 모델 훈련 시 성능을 향상시키는 기법입니다. 2015년에 Sergey Ioffe와 Christian Szegedy가 제안한 이 방법은 현재 대부분의 딥러닝 모델에서 널리 사용되고 있습니다.
배치 정규화의 주요 기능과 장점은 다음과 같습니다:
- 정규화 과정: 각 배치의 데이터를 평균이 0, 분산이 1이 되도록 정규화합니다. 즉, 각 층의 입력 분포를 일정하게 유지합니다.
- 내부 공변량 이동(Internal Covariate Shift) 감소: 훈련 과정에서 각 층의 입력 분포가 계속 변하는 문제를 해결합니다.
- 학습 속도 향상: 더 높은 학습률을 사용할 수 있게 하여 훈련 속도를 크게 향상시킵니다.
- 정규화 효과: 가중치 정규화와 유사한 효과를 제공하여 과적합을 줄입니다.
- 그래디언트 소실/폭발 문제 완화: 깊은 네트워크에서 발생하는 그래디언트 소실이나 폭발 문제를 줄여줍니다.
그렇다면 왜 우리는 Batch Norm으로 위의 그림과 같이 다른 Batch를 비슷하게 정규화 하는 것일까요?
- 학습 과정의 불안정성 문제: 딥러닝 모델을 훈련할 때, 앞쪽 층의 가중치가 조금만 변해도 뒤쪽 층에 전달되는 데이터 분포가 크게 변할 수 있습니다. 이렇게 되면 뒤쪽 층들은 지속적으로 변화하는 입력 분포에 적응해야 하므로 학습이 느려지고 불안정해집니다.
- 그래디언트 소실과 폭발 문제: 깊은 신경망에서는 역전파 과정에서 그래디언트가 점점 작아지거나(소실) 너무 커지는(폭발) 문제가 발생합니다. 배치 정규화는 활성화 값들을 적절한 범위로 유지시켜 이 문제를 완화합니다.
- 학습률 민감성 감소: 배치 정규화가 없으면 적절한 학습률을 찾기가 매우 어렵습니다. 너무 크면 발산하고, 너무 작으면 학습이 너무 느립니다. 배치 정규화는 더 넓은 범위의 학습률에서 안정적으로 학습할 수 있게 해줍니다.
- 초기 가중치에 대한 의존성 감소: 배치 정규화 없이는 가중치 초기화 방법이 매우 중요합니다. 배치 정규화를 사용하면 초기화 방법에 대한 민감도가 줄어듭니다.
- 정규화 효과로 인한 일반화 성능 향상: 배치 정규화는 약한 형태의 정규화 역할을 하여 모델이 훈련 데이터에 과적합되는 것을 방지하고 테스트 데이터에 대한 성능을 향상시킵니다.
그렇다면 그래디언트 소실과 폭발은 무엇인가요?
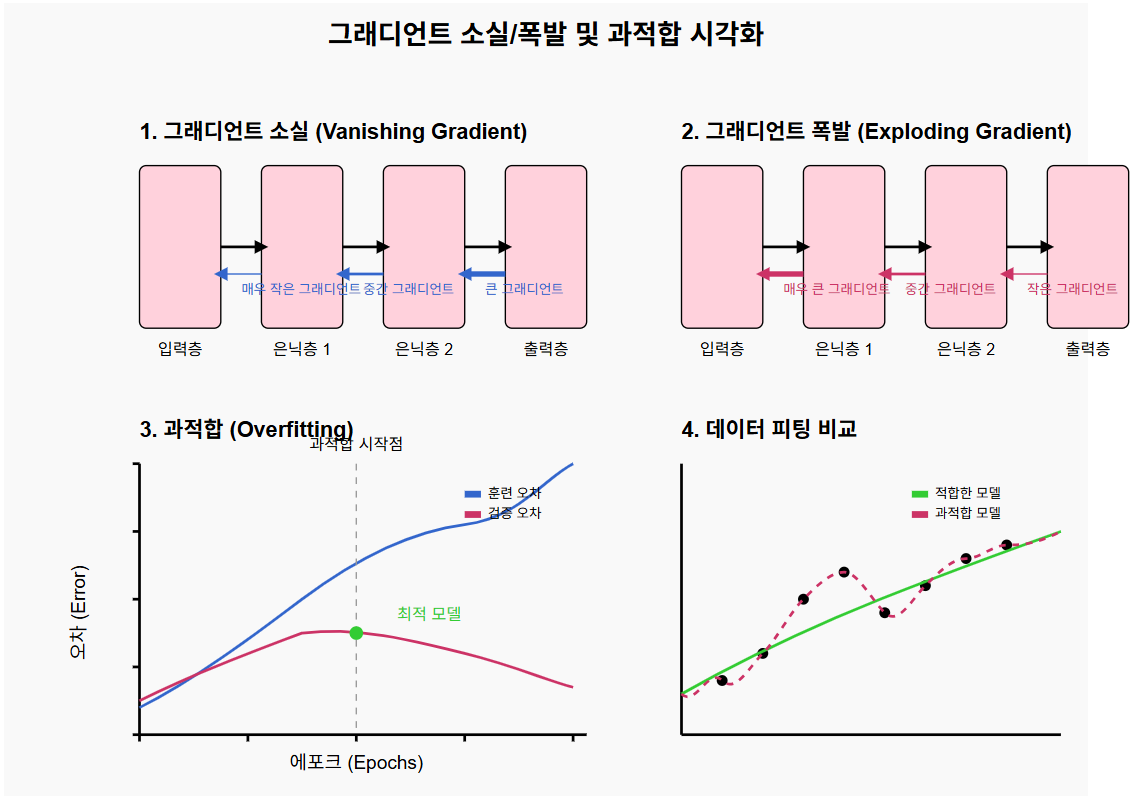
그래디언트 소실(Vanishing Gradient)
- 수학적 원인: 활성화 함수(특히 시그모이드나 하이퍼볼릭 탄젠트)의 미분값이 특정 구간에서 매우 작습니다(0에 가까움).
- 전파 과정: 역전파 시 이 작은 미분값들이 곱해지며 점점 더 작아집니다.
- 결과: 앞쪽 층으로 갈수록 그래디언트가 거의 0에 가까워져, 가중치가 거의 업데이트되지 않습니다.
- 실질적 의미: 깊은 네트워크의 앞쪽 층들은 학습이 매우 느리거나 거의 이루어지지 않게 됩니다.
그래디언트 폭발(Exploding Gradient)
- 수학적 원인: 가중치 초기화가 부적절하거나, 네트워크 구조에 문제가 있을 때 발생합니다.
- 전파 과정: 역전파 시 그래디언트 값이 점점 커지게 됩니다.
- 결과: 그래디언트 값이 너무 커져 가중치 업데이트가 불안정해집니다.
- 실질적 의미: 학습이 발산하고 모델이 수렴하지 않게 됩니다.
과적합(Overfitting)
- 통계적 원인: 모델이 훈련 데이터의 노이즈나 특이점까지 학습하게 됩니다.
- 복잡성 측면: 모델의 용량(파라미터 수)이 필요 이상으로 클 때 발생합니다.
- 데이터 관점: 훈련 데이터가 적거나 편향되어 있을 때 더 심해집니다.
- 결과: 훈련 데이터에서는 성능이 매우 좋지만, 테스트 데이터에서는 성능이 떨어집니다.
- 실질적 의미: 모델이 일반화 능력을 잃고 특정 훈련 데이터에만 최적화되어 새로운 데이터에 대응하지 못하게 됩니다.
728x90
반응형
'전공 > 신경망딥러닝' 카테고리의 다른 글
| 신경망딥러닝(13)_큰 dataset 처리 with tf dataset API (0) | 2025.04.17 |
|---|---|
| 신경망딥러닝(11)_딥러닝 학습 순서 전체 정리 (0) | 2025.04.10 |
| 신경망딥러닝(10)_전이 학습(Transfer Learning) (1) | 2025.04.08 |
| 신경망딥러닝(1)_개요 (0) | 2025.04.03 |